Metadata
Codebook
What is a codebook?
A codebook is a simple dictionary or lexicon for the data gathered in your experiments. Even though sharing data is becoming a widely practiced method among scientists, making your data understandable for others (and yourself in the future) is another issue Open Science has to deal with. Imagine having 24 variables called Var1, Var2, Var3… Codebooks require scientists to carefully label their variables, explain in a few words what that variable means, its type and also the data range and the labels for its values.
Why should I use it?
Some journals and data sharing sites encourage their users to upload data and also a codebook to make it easier for other researchers to re-use existing datasets.
In all APA journals, every author has to sign the Certification of Compliance With APA Ethical Principles (https://www.apa.org/pubs/authors/ethics.pdf), which includes an article concerning data sharing. According to that, no author should withhold published data from competent professionals. Not being able (or willing, but that’s another issue) to do that, or not making your dataset clear to follow can cause problems.
Many times the data (its labels, variable names and types) you request are not precise or thorough enough for others to read and understand. Writing a codebook makes it much easier for researchers to share, understand, re-analyze, re-evaluate data in replications and meta-analyses. This way you also encourage other scientists in your field to generalize data types and names, to make experiments and results more transparent and to follow the principles of Open Science.
How can I create a codebook for my research?
There are several ways to create your very own codebook.
You can find a very good (but a bit long) example here for a written document type, this is an HTML type, and this link can give you a practical and proper guide to create codebooks in spreadsheet format.
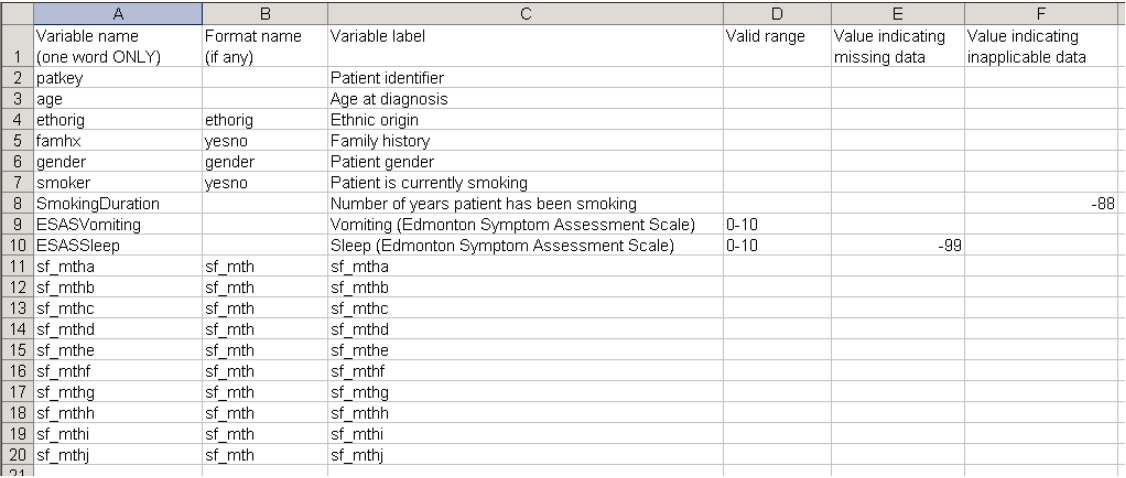
(Credit to P. Bélisle & L. Joseph, copied from here)
Another useful tool was created by R. Arslan to make storing and managing data via codebooks easier. You can download the program for the codebook in R from github (link) or read the documentation here.
File and data standards
File and folder naming
To create widely understandable and transparent data, having a good dataset is not enough. Researchers are highly recommended to make file and folder names comprehensible for themselves and their fellow labmembers. This can help experimental data keep even more organized.
https://www.force11.org/group/fairgroup/fairprinciples
https://librarycarpentry.org/Top-10-FAIR/
http://adv-r.had.co.nz/Style.html
https://docs.google.com/document/d/1u8o5jnWk0Iqp_J06PTu5NjBfVsdoPbBhstht6W0fFp0/edit?usp=sharing
File formats
One should use no proprietary file formats when sharing the materials and data files of a project. The Psych Data Standard (see the webpage for more information: https://psych-ds.github.io/)
File version control
Throughout a research project several files are created (different files for the materials, data, the analysis, and the manuscript) and changed frequently. Without version control, researchers usually create different versions of these files to track the changes. However, in collaborative work different versions of the same file can highly increase the chance of a mistake.
Version control systems solve this problem by keeping track of the changes of a file in a timestamped and organized manner. One of the most popular version control system is Git and it is widely used through the online service Github. Github can be used to easily and safely share analysis code, data and any other document with collaborators during the project development or to share it publicly with other researchers at the end of the project.
All of the changes made through a Git version control system will be well documented and can be commented on so that your collaborators and yourself can see what was the decision behind each change.
- To use Github, first register on the following web page: https://github.com/
- If you are a student you can upgrade your services with a student developer pack
- If you have a github account you can create a repository (which is private or public)
- You can add collaborators to the repository
- You can then clone the online repository to your computer and work on its content. The easiest to use application for this is the free Github Desktop application that you can download from here: https://desktop.github.com/. However, you can do it by code as well
- Now, you can work on the content of your repository on your computer. Do not forget to commit (i.e. save the changes that you have made since the last commit with comments and a timestamp) every bigger change, and if you are finished with the work, push (i.e. upload the changes that you have locally made on your computer to the remote repository) your changes to the online repository, so the collaborators can work on the newest version of the files.
- You can add the content of your Github repository to the OSF repository of the project as well, if you’d like to
You can find a detailed tutorial using RStudio on Github in this open access article: https://journals.sagepub.com/doi/10.1177/2515245918754826
Saving and archiving
Useful links on data handling:
- Guideline on Data Handling and Methods Reporting (DHMR) 2017
- Data Management in Psychological Science
- Data sharing in clinical trials
- Introduction to privacy-preserving data analysis
- Protect User Data with Differential Privacy
When saving data, it is important to assure that it is stored in a secure and robust manner – meaning, it is not stored on only one storage device, and that there are backups available. As most psychological research data is easily digitizable, it is advised to store the data in a digitized format, and to store non-digitizable data at the institution – ensuring that access to the data is maintained even in the case of a change in affiliations. If one wants to make data available in a repository, it is important that it is trustworthy – some characteristics of a trustworthy repository are long-term data storage, accessibility, identifiability, clarification of data property rights, and the option to store data publicly as well as non-publicly (x).
According to this guideline the stored data package must include metadata (when and by whom the files were created/edited), the raw database, all the digital research material that was used, as well as the syntax, computer codes and statistical logbooks used in statistical analysis and the processed database.
According to the APA guideline, data should be retained and available for at least 10 years, following the publication date of the article.
Protection of data privacy
In some cases it is enough to delete variables containing personal information to anonymize a dataset as the remaining data is not enough to use for the identification of the participants. It is important however to always ask for the permission of the local IRB committee. Differentiation of source data and raw data is also key to protect participant privacy. Source data is the dataset coming straight from the data collection software (eg. Qualtrics, google forms, Matlab, etc.) Raw data however is a preprocessed dataset without private data (e.g. Name, Address, NEPTUN id, etc.). Raw data is also processed for further statistical analysis.
When sharing open data always make sure you share raw data and not source data.
One method to ensure data privacy is the differential privacy method that mixes general white noise in the data. To do it there is an R package see here: https://github.com/brubinstein/diffpriv
Policies for sharing and access
Deciding what to share
- If the whole dataset can be anonymized: Inform participants about potential secondary use of anonymized data, no additional written consent is needed.
- If part of data is non-anonymized (e.g., videos): Obtain consent for data use in the current project and/or additional consent for secondary use, inform them about storing their data for 10 years, inform them about withdrawal rights and ways.
Data Sharing Types
Type 1: Sharing of data that are part of a publication
- With the manuscript, the “data sharers” (those who collected the data) should make primary data available needed to reproduce the results.
- Data from non-used measures have to be reported, but only need to be shared when used in publication or when third-party funded project is concluded.
- Exceptions to Data Sharing Type 1 should be declared.
Type 2: Sharing after project completion
- This applies particularly to studies funded by public organization and for which the scope is properly defined.
- DFG Guidelines: the data that have been collected should be made available to the public immediately or within a few months after the completion of the research.
- This includes all non-used data, and all relevant materials to make sense of it (scripts, code books, stimuli).
- Examples of irrelevant data: data based on flawed code, highly exploratory pilot data.
- To counter publication bias, one should make the “null results” (data that did not yield the expected outcome) publicly available.
Rights and duties of sharers and users
Rights of data sharer
- “Researchers who produce primary data have the right of first use”. In case of more than one primary researchers, this right should be negotiated in the group.
- “Data sharers can define an embargo for secondary use”, meaning they can make the not yet published data inaccessible for a certain time period.
- “Data sharers further have the right to know who uses their data and for which purposes”. Even if there is an automatic notification for data usage, the secondary users should always inform the primary researchers of their data use.
Duties of data sharers
- Data sharers need to share their data in a way that anyone can meaningfully use them.
- informed consent of the participants should be made available
- all data and metadata should be described and documented.
- Data sharing embargo has to be announced as soon as the primary data are stored, and an ending date should be specified initially.
- Generally, researchers should not impose an embargo on Type 1 datas.
Duties of secondary users
- Secondary users should always contact the data sharers when using their data.
- Secondary users should not be motivated by damaging a researcher’s reputation. Also, data shararse can not prevent publication of contradicting results from reanalysis.
- Secondary users should always cite the data adequately. In case of reanalysis, second user should always cite the original dataset, not their own version (which can be transformed or recoded).
- Secondary users should not infringe any existing copyright laws.
- Finally, secondary use of data needs to follow the same regulations and requirements as the original research.
Based on: Schönbrodt, F., Gollwitzer, M., & Abele-Brehm, A. (2017). Data management in psychological science: Specification of the DFG guidelines.